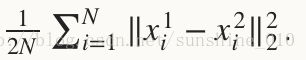层
要创建Caffe模型,您需要在协议缓冲区定义文件(prototxt)中定义模型体系结构。
Caffe图层及其参数在caffe.proto中项目的协议缓冲区定义中定义。
数据层
数据通过数据层进入Caffe:它们位于网络的底部。 数据可以来自高效的数据库(LevelDB或LMDB),直接来自内存,或者当效率不是关键时,可以来自HDF5或通用映像格式的磁盘上的文件。
常用的输入预处理(平均减法,缩放,随机裁剪和镜像)可以通过指定一些图层的TransformationParameters来实现。 当TransformationParameter不可用时,bias, scale和crop层可能有助于转换输入。
Image Data - 读取原始图像。
Database - 从LEVELDB或LMDB读取数据。
HDF5 Input - 读取HDF5数据,允许任意尺寸的数据。
HDF5 Output - 将数据写入HDF5。
Input - 通常用于正在部署的网络。
Window Data - 读取窗口数据文件。
Memory Data - 直接从内存中读取数据。
Dummy Data - 用于静态数据和调试。
请注意,Python图层可用于创建自定义数据图层。
视觉层
视觉层通常将图像作为输入,并产生其他图像作为输出,虽然他们可以采取其他类型和尺寸的数据。 现实世界中典型的“图像”可能有一个颜色通道(c = 1),如在灰度图像或三个颜色通道(c = 3)如RGB(红,绿,蓝)图像。 但在这种情况下,图像的显着特征是其空间结构:通常图像具有一些有意义的高度h> 1宽度w> 1。 这种2D几何形状自然适合于如何处理输入的某些决定。 具体地说,大多数视觉层通过对输入的某个区域应用特定的操作来产生输出的对应区域。 相比之下,其他层次(除少数例外)忽略了输入的空间结构,有效地把它看作是维度为chw的“一个大向量”。
Convolution Layer - 用一组可学习的滤波器卷积输入图像,每个滤波器在输出图像中产生一个特征图。
Pooling Layer - 最大值,平均值或随机池。
Spatial Pyramid Pooling (SPP)
Crop - 进行切块转化。
Deconvolution Layer - 转置卷积。
Im2Col - 不再使用的遗留助手层。
递归层
Recurrent
RNN
Long-Short Term Memory (LSTM)
通用层
Inner Product - 全连接的层。
Dropout
Embed - 用于学习单编码向量的嵌入(以索引作为输入)。
归一化层
Local Response Normalization (LRN) - 通过对局部输入区域进行标准化来执行一种“横向抑制”。
Mean Variance Normalization (MVN) - 执行对比度标准化/实例标准化。
Batch Normalization - 对小批量执行标准化。
bias 和 scale 层可以有助于与规范化相结合。
激活/神经元层
一般而言,激活/神经元层是单个元素的操作符,取一个底部的blob并产生一个相同大小的顶部blob。 在下面的图层中,我们将忽略输入和输出尺寸,因为它们是相同的:
输入
n * c * h * w
产量
n * c * h * w
ReLU / Rectified-Linear and Leaky-ReLU - ReLU和Leaky-ReLU纠正。
PReLU -参数化的ReLU。
ELU - 指数线性整流。
Sigmoid
TanH
Absolute Value
Power - f(x) = (shift + scale * x) ^ power.
Exp - f(x) = base ^ (shift + scale * x).
Log - f(x) = log(x).
BNLL - f(x) = log(1 + exp(x)).
Threshold -在用户定义的阈值处执行步进功能。
Bias - 增加了一个可以学习或修复的blob的偏离。
Scale -按可以学习或修正的数量缩放一个blob。
实体层
Flatten
Reshape
Batch Reindex
Split
Concat
Slicing
Eltwise - 单个元素的操作,如产品或两个blob之间的总和。
Filter / Mask - 遮罩或者选择用最后的blob输出。
Parameter - 启用参数在层之间共享。
Reduction - 使用诸如总和或平均值等操作将输入blob减少为标量blob。
Silence - 防止在训练期间打印最顶层的blob。
ArgMax
Softmax
Python - 允许自定义Python图层。
损失层
损失通过将产出与目标进行比较并分配成本来最小化来推动学习。 损失本身是通过正向通过计算的,通过反向通过计算损失的梯度w.r.t. 。
Multinomial Logistic Loss对数损失函数
Infogain Loss - MultinomialLogisticLossLayer对数损失函数的一般化。
Softmax with Loss - 计算输入的softmax的多项式逻辑损失。 它在概念上与softmax层相同,后面跟着一个多项式对数损失层,但是提供了一个更加数字化的稳定梯度。
Sum-of-Squares / Euclidean - 计算两个输入的差的平方和,
Hinge / Margin - 铰链损失层计算一个对所有铰链(L1)或平方铰链损失(L2)。
Sigmoid Cross-Entropy Loss - 计算交叉熵(logistic)损失,通常用于预测被解释为概率的目标。
Accuracy / Top-k layer - 将输出作为对目标的准确度进行评分 - 这实际上不是损失,也没有反向的步骤。
Contrastive Loss

微信


支付宝