














UniLM论文全名为Unified Language Model Pre-training for Natural Language Understanding and Generation,译为自然语言理解与生成的统一预训练语言模型,来自于微软研究院。
论文地址:paper
论文代码:code
前一段时间一直再撸这篇论文的code,想用自己的数据也搞一个即能生成,又能理解的model;可是,我再次打开github时,发现了微软研究院又搞了一篇unilm-v2出来(我真的心累,还是没能紧跟上时代的步伐,论文看的不够快,代码写的不过精,总也不动腿脚都不好了,sad~~~),不过这篇unilm-v2的code没有realize(过几天再分享v2)。
目前,预训练的语言模型(Language model )已经大幅地提高了各种自然语言处理任务的水平。它一般使用大量文本数据,通过上下文来预测单词,从而学习到文本上下文的文本表示,并且可以进行微调以适应后续任务。不同类型的预训练语言模型一般采用不同的预测任务和训练目标,如表1所示。ELMo模型学习两个单向语言模型(unidirectional LM):前向语言模型从左到右读取文本进行编码,后向语言模型从右到左读取文本进行编码。GPT模型使用Transformer编码解码器从左到右的一逐字地预测文本序列。BERT模型使用一个双向Transformer编码器通过被掩字上下文来预测该掩蔽字。
尽管BERT模型已经显著地提高了大量自然语言理解任务的效果,但是由于它的双向性使得它很难应用于自然语言生成任务。

因此,作者提出了一个新的统一预训练语言模型(UniLM),既可以应用于自然语言理解(NLU)任务,又可以应用于自然语言生成(NLG)任务。UniLM模型的框架与BERT一致,是由一个多层Transformer网络构成,但训练方式不同,它是通过联合训练三种不同目标函数的无监督语言得到,如表2所示。

为了使三种不同的目标函数运用到同一种模型框架中,作者设计了三类完型填空任务,像BERT模型一样,去预测被掩的token(这是该篇论文的核心)。下面将详细进行介绍,如何设计这三类完型填空任务的。
模型框架如图1所示,在预训练阶段,UniLM模型通过三种不同目标函数的语言模型(包括:双向语言模型,单向语言模型和序列到序列语言模型),去共同优化同一个Transformer网络;为了控制对将要预测的token可见到的上下文,作者使用了不同的self-attention mask来实现。换句话说,就是通过不同的掩码来控制预测单词的可见上下文词语数量,实现不同的模型表征。
单向语言模型:分为从左到右和从右向左两种,从左到右,即仅通过被掩蔽token的左侧所有本文来预测被掩蔽的token;从右到左,则是仅通过被掩蔽token的右侧所有本文来预测被掩蔽的token。
双向语言模型:与BERT模型一致,在预测被掩蔽token时,可以观察到所有的token。
序列到序列语言模型:如果被掩蔽token在第一个文本序列中,那么仅可以使用第一个文本序列中所有token,不能使用第二个文本序列的任何信息;如果被掩蔽token在第二个文本序列中,那么使用一个文本序列中所有token和第二个文本序列中被掩蔽token的左侧所有token预测被掩蔽token。
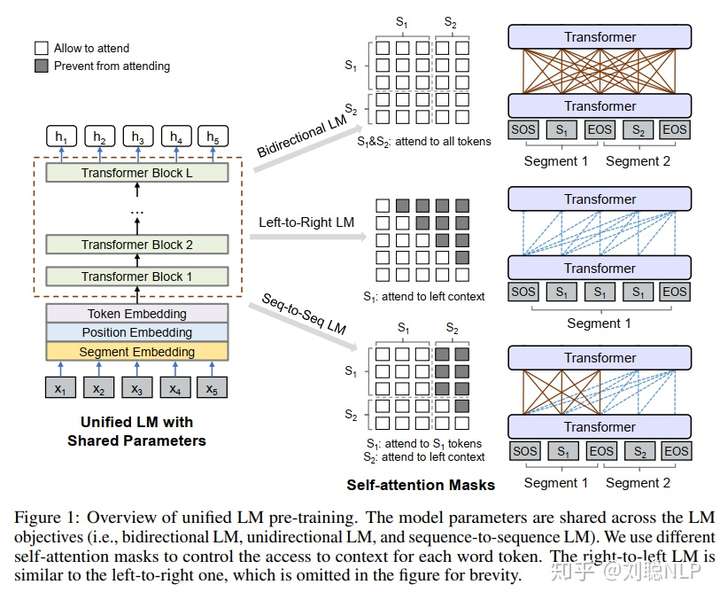
对于单向语言模型,模型输入是一个单独的本文;对于双向语言模型和序列到序列的语言模型,模型输入是一个文本pair对。并且在第一个文本开始前加上【SOS】 token,在每一个文本末尾加上【EOS】 token,用于表示不同文本的分割(与BERT相似,只不过将【CLS】换成了【SOS】,将【SEP】换成了【EOS】)。在NLG任务上,【EOS】还可以作为文本生成结束的标志。输入表征跟BERT模型也是一致的,由字向量,位置向量和句子段落向量组合而成。在文本处理过程中,使用WordPiece把token都处理成了subword(应该是增强模型的生成能力)。
因为,UniLM模型使用多语言模型任务进行训练;所以,作者对于不同的语言模型使用了不同句子段落向量(code中显示,双向对应0和1;单向left-right对应2;单向right-left对应3;序列对应4和5)。
模型结构与Bert一致,每个Transformer中使用多头self-attention结构组成,公式如下:
其中, 表示该字词是否可以被其他字词看到。如图1所示,不同的任务,我们赋予不同的掩码。例如:双向语言模型,我们就允许所有字词都可以相互看见。
作者设计了三种类型的完型填空任务,共同优化同一个transformer框架。在完型填空任务中,我们在文本中随机选择一些token,使用特殊标记【Mask】进行替换;将文本输入到 Transformer网络,计算出对应的输出向量,再通过softmax分类器预测【Mask】到底属于字典中的哪一个token。
UniLM模型参数通过最小化预测token和标准token的交叉熵来优化。三种类型的完型填空任务可以完成不同的语言模型运用相同的程序程序训练。
单向语言模型:有从右到左和从左到右两者,以从左到右为例进行介绍。每个特殊标记【Mask】的预测,仅采用它自身和其左侧的token进行编码。例如,我们预测序列 中的【Mask】,我们仅可以利用
、
和它自身进行编码。具体操作,如图1所示,使用一个上三角矩阵来作为掩码矩阵。阴影部分为
,空白部分为0。
双向语言模型:跟Bert模型一致,每个特殊标记【Mask】的预测,可以使用所有的token进行编码。例如,我们预测 序列 中的【Mask】,我们仅可以利用
、
、
和它自身进行编码。具体操作,如图1所示,使用全0矩阵来作为掩码矩阵。
序列到序列语言模型:如果预测的特殊标记【Mask】出现在第一段文本中时,仅可以使用第一段文本中所有的token进行预测;如果:如果预测的特殊标记【Mask】出现在第二段文本中时,可以采用第一段文本中所有的token,和第二段文本中该预测标记的左侧所有tokne以及它本身。例如,我们预测序列 中的【mask1】时,除去【SOS】和【EOS】,我们仅可以利用
、
、
和它自身进行编码;预测【mask2】时除去【SOS】和【EOS】,我们仅可以利用
、
、
、
、
、
和它自身进行编码。具体操作,如图1所示。
由于在训练时,将源文本和目标文本结合进入模型,使模型可以含蓄地学习到两个文本之间关系,可以做到seq-to-seq的效果。
NSP任务:对于双向语言模型,与bert模型一样,也进行下一个句子预测。如果是第一段文本的下一段文本,则预测1;否则预测0。
以上就是模型核心部分,用一句来总结一下,就是对于不同的语言模型,我们可以仅改变self-attention mask,就可以完成联合训练。
在模型预训练过程中,在一个训练batch中,使用1/3的数据进行双向语言模型优化,1/3的数据进行序列到序列语言模型优化,1/6的数据进行从左向右的单向语言模型优化,1/6的数据进行从右向左的单向语言模型优化(如何实现呢?个人理解可以使用pipline方式进行训练,loss进行累加)。模型结构与BERT-large模型一致,由一个24层1024隐藏节点和16个头的Transformer编码器组成,约有340M大小参数,并由训练好的BERT-large模型初始化参数。token掩码的概率为15%,在被掩掉的token中,有80%使用【MASK】替换,10%使用字典中随机词进行替换,10%保持越来token不变,与BERT模型一致。此外,在80%的情况下,每次随机掩掉一个token,在剩余的20%情况下,掩掉一个二元token组或三元token组。
以上就是UniLM模型的全部介绍,重点还是如何设计统一的语言模型,通过修改mask的方式,实现同一程序做不同的任务;也可以理解成,通过不同任务,去优化同一分模型参数,在不同任务中,模型参数是共享的。论文实验部分,介绍的在自然语言理解和自然语言生成的效果,感兴趣的同学可以自行阅读。
提醒一下,序列到序列语言模型,在pretrain过程中,mask token的选取,是可以出现在第一个文本序列中,也可以出现在第二个文本序列中;但是到了fine-tuning阶段时,mask token仅出现在第二个文本序列中,因为我们需要通过第一个文本生成第二个文本。
UniLM模型,本人亲测有效呦~~~~~在自然语言理解和生成任务上,都有不错的效果。

微信


支付宝






